I used GitHub as a CMS
Recently I decided to migrate my personal portfolio from Next.js to Remix just for fun. All the data was stored in plain json in the project. But now I decided to make it a bit more interesting.
Choosing a CMS
I looked up a bunch of options for content management, and I wasn't impressed. My idea was to spend as little money as possible. The website doesn't bring me any revenue, so why spend money on it?
Sure, I could go with Keystone or Strapi and self-host it. But it's just mainstream, what's fun in that?
So, after a quick research, I decided to reinvent a CMS 🤓
I created a fresh repo on GitHub, generated an API key, and started writing a connector.
Storing data
I decided to go with a simple structure. My 'CMS' will only have 3 types of data. First, I'll need a structure for pages. Each page is represented as json object having page's meta and sections it has. We'll get to the sections later, not you can see an example of the resulting page object
{
"title": "Contact me - Artem Novoselov",
"description": "Fullstack Software Developer to build your next website",
"sections": ["contacts"],
"headerLinks": [
{ "name": "About", "href": "/" },
{ "name": "Contact", "href": "/contact" },
{ "name": "Blog", "href": "/blog" }
]
}
Second, each page is divided into sections. Each of them requires its own type of data. Again it's json but the structure will be unique for each section.
Third, I want to include a blog. At this point it gets a bit more complicated. Sure, I can use json for it as well, but writing content in json? No, I'm not doing that. For the posts I went with a simple markdown with frontmatter for metadata such as
title: I used GitHub as a CMS
description: You may not need a CMS for you personal project.
tags: react,remix,github
published: true
datePublished: 12/11/2024
I ended up with the following project structure
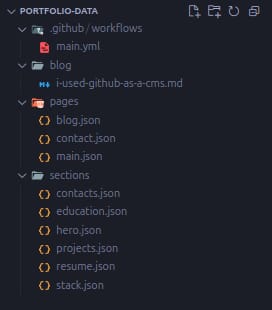
Fetching GitHub
GitHub's API is extremely rich in functionality, and complex at some points. Luckily, I won't need a lot. The only method I'll use is /repos/{owner}/{repo}/contents/{path}. You can check the docs there.
This endpoint returns either a file's content with metadata or a list of files' metadata in a requested directory. This is enough, actually. Writing a couple of fetch requests to separate the logic of working with pages, sections, and blog posts didn't take much time and didn't require anything deeper than the basic understanding of fetch.
Though it got complex with blog. The website needs a way to not only fetch a specific post but also to display all of them. With currently made decisions it needs n+1 requests: 1 to get the list of all files and the rest is to fetch the contents for metadata. And this sounds really scary. Thankfully, I can optimize it.
Less requests
The simplest solution imo is to cache the calculated data. The process for fetching the list of posts can be broken down like this
- Get the list of files
- Get file's content
- Parse file
- Get file's metadata
- Calculate approximate reading time
And the points 2-4 happening in a loop until there's no files left.
To reduce the latency and the amount of calculations I decided to use Redis and store cache the responses there. This way all this requests will only happen once and then the website will just get it from storage.
Keeping data up to date
After a request is cached the data will be served from Redis and the changes made to the repo won't be reflected. This is a big problem as I want my content to be dynamic. I can introduce cache expiration time to address it but it'll lead to extra requests for the cases when the content wasn't actually updated 🤔.
The solution appeared to be simple. I've added a GitHub action which make a flush call to the database on merges and pushes. Pretty straight-forward imo. Just like that
name: Revalidate cache
on:
push:
branches:
- main
pull_request:
branches:
- main
types:
- closed
jobs:
revalidate-redis-cache:
runs-on: "ubuntu-latest"
env:
REDIS_URL: ${{ secrets.REDIS_URL }}
REDIS_TOKEN: ${{ secrets.REDIS_TOKEN }}
steps:
- run: |
curl --location "$REDIS_URL/flushall" \
--header "Authorization: Bearer $REDIS_TOKEN"
Conclusion
There won't be one 😅. I just had fun re-inventing a CMS and decided to share it with the community. The starting point for a project doesn't have to be costly. Just use the stuff that solves your problem and not a hyped must-have, the most of the features of which you may not event need.